・Development of a speech training system by lip
movements
| Apr. 1.2023 |
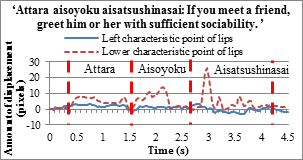
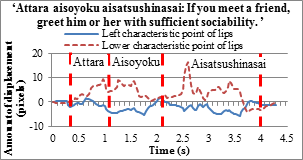
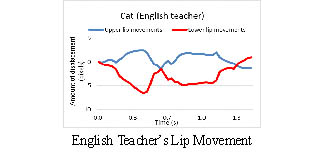
Above left figure is the line graphs of the English teacher’s lip movements
and Participant A’s lip movements when they pronounced the word “cat”.
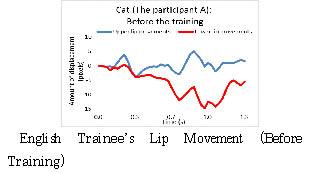
In the middle one is Participant A’s lip movements before starting the
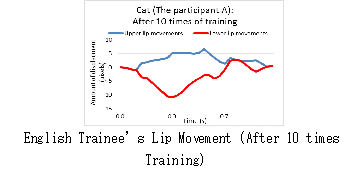
training. On the right side one is Participant A’s lip movements after
the 10 repetitions of the training. The English teacher opened her mouth
widely after she pronounced /kæ/, while Participant A did not open her
mouth widely and did not speak clearly. However, her lip movements improved
somewhat and become more like the English teacher’s after the 10 repetitions
of the training.
If you use "Edge", movie is not played, Please use "Internet
Explorer" or tclick he sentence below
.
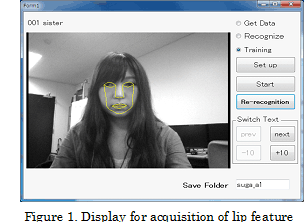
Figure 1 is a
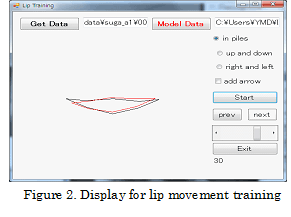
display for acquisition of lip feature points. Figure 2 is a display for lip
movement training. When you are recognized by a lip feature point collecting
application, your face feature points in Figure 1 are shown by it. This
application was developed in our laboratory by using a Seeing Machines Inc.'s
Face API. To operate this application: first, select a file for training from
“Set up” button and type a file name for saving data. Second, start training by
clicking “Start” button. When you close your mouth, the application recognizes
your mouth and you can start pronouncing. If you are not recognized by the
application, click “Re-recognition” button. Third, click “Stop” button for
stopping recording. Fourth, a lip movement training display is shown after stopping
recording. A red line diagram in Figure 2 is teacher’s lip movement that is
used as model data. A black line diagram in Figure 2 is participants lip
movements. When you click “Start” button in Figure 2, you can compare your lip
movements with teacher’s lip movements.
|
・Development of a speech training system by lip
movements |
|